Dia 46 de quarentena: finalmente resolvi fazer um blog pra juntar tudo que tenho feito em R nas horas vagas. Para o primeiro post, vou utilizar um dos meus datasets favoritos, o Spotify Charts, que disponibiliza os rankings diários e semanais das 200 músicas com maior número de streamings no Spotify. O post será dividido em 2 partes: aquisição e análise dos dados.
Aquisição de dados
Primeiramente, vamos carregar os pacotes que iremos usar:
library(rvest)
library(tidyverse)
library(scales)
library(janitor)
library(lubridate)
library(furrr)
library(glue)
library(tidytext)
theme_set(theme_light())No topo direito da página, há uma opção para exportar os dados em formato .csv. No entanto, cada exportação gera apenas os dados do dia selecionado. Se copiarmos o link correspondente ao botão, veremos que segue o seguinte padrão spotifycharts.com/regional/br/daily/YYYY-MM-DD/download com YYYY-MM-DD correspondendo a data a ser exportada. Para exportar todas as datas que desejamos, então, basta substituir o espaço destinado a elas no link. Vamos fazer o download da tabela de 2 dias atrás para ver como o resultado é disponibilizado:
tabela_individual <- read_csv(glue("https://spotifycharts.com/regional/br/daily/{Sys.Date() - 2}/download"))
tabela_individual## # A tibble: 201 x 5
## X1 X2 X3 `Note that these figures are g~ X5
## <chr> <chr> <chr> <chr> <chr>
## 1 Posit~ Track Name Artist Streams URL
## 2 1 A Gente Fez~ Gusttav~ 521613 https://open.sp~
## 3 2 Don't Start~ Dua Lipa 443213 https://open.sp~
## 4 3 Liberdade P~ Henriqu~ 413044 https://open.sp~
## 5 4 BRABA Luísa S~ 394097 https://open.sp~
## 6 5 Tudo no Sig~ Vytinho~ 364649 https://open.sp~
## 7 6 Graveto - A~ Marília~ 349974 https://open.sp~
## 8 7 Litrão - Ao~ Matheus~ 342073 https://open.sp~
## 9 8 Roses - Ima~ SAINt J~ 331409 https://open.sp~
## 10 9 Rave de Fav~ MC Lan 324164 https://open.sp~
## # ... with 191 more rowsPercebemos que o resultado sai com um texto acima do nome das colunas, logo precisaremos especificar que essa primeira linha deve ser ignorada na hora de ler a tabela. Além, disso, precisaremos criar uma coluna para especificar a data, e usar a função clean_names do pacote janitor para padronizar o nome das colunas.
Antes de baixar todas as tabelas, no entanto, precisamos saber quais dias estão disponíveis para download. Para isso, será preciso o uso de webscraping, ou seja, extrair dados diretamente de um website. Faremos isso com o auxilio do programa Selector Gadget, uma extensão do Chrome que permite identificar qual parte do CSS do site você deseja extrair, conforme mostra a imagem abaixo:
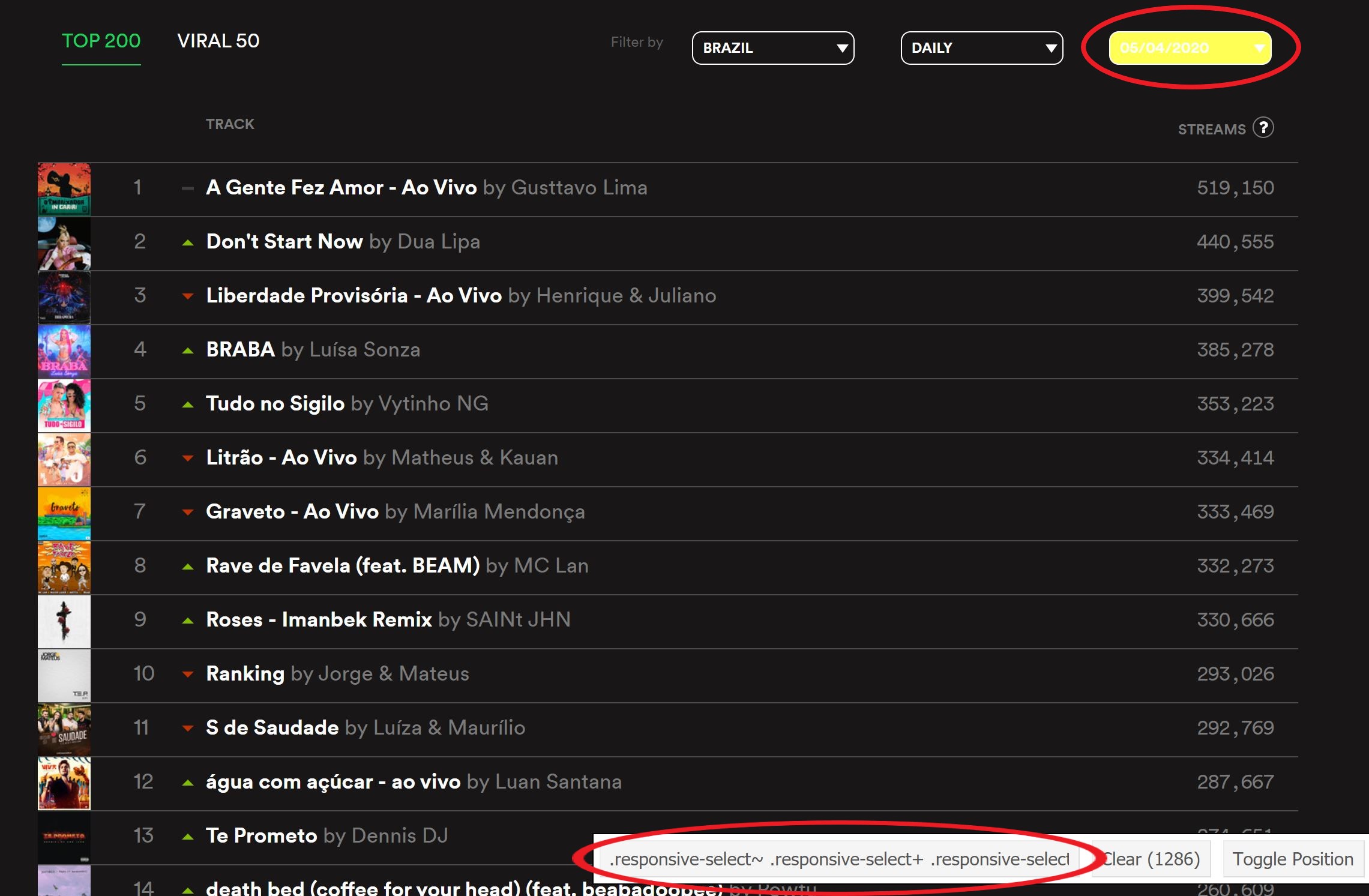
Usando os pacotes rvest e purrr, extraímos as datas disponíveis:
datas_disponiveis <- read_html("https://www.spotifycharts.com/regional/br/daily/") %>%
html_nodes(".responsive-select~ .responsive-select+ .responsive-select .responsive-select-value , .responsive-select li") %>%
map(html_text) %>%
map_chr(rbind)
head(datas_disponiveis)## [1] "Global" "United States" "United Kingdom" "Andorra"
## [5] "Argentina" "Austria"tail(datas_disponiveis)## [1] "01/06/2017" "01/05/2017" "01/04/2017" "01/03/2017" "01/02/2017"
## [6] "01/01/2017"Podemos perceber que, além das datas disponíveis, também foram extraídos os países disponíveis. Portanto, precisamos filtrar para que fiquem apenas as datas e colocá-las no formato YYYY-MM-DD (vamos também filtrar apenas datas do ano de 2019 e 2020).
datas_disponivels_filtradas <- datas_disponiveis %>%
enframe(name = NULL) %>% # transformando o vetor em tabela
filter(str_detect(value, "\\d")) %>% # deixando apenas valores com presença de numeros
mutate(value = mdy(value)) %>%
filter(year(value) %in% c(2019, 2020)) %>% # deixando apenas anos 2019 e 2020
distinct(value) %>%
pull(value)
head(datas_disponivels_filtradas)## [1] "2020-05-06" "2020-05-05" "2020-05-04" "2020-05-03" "2020-05-02"
## [6] "2020-05-01"Agora que temos nossas datas, podemos fazer download de todas as tabelas de uma vez só, criando uma função que será repetida para cada data. Usaremos o pacote furrr, que aplica as funções do pacote purrr em paralelo, ganhando velocidade. A próxima parte pode levar alguns minutos para concluir. Se você preferir, pode baixar os dados diretamente daqui.
funcao_tabelas <- function(x){
read_csv(glue("https://spotifycharts.com/regional/br/daily/{x}/download"),
skip = 1) %>%
clean_names("upper_camel") %>% # padronizando nomes das colunas
mutate(Date = x)
}
plan(multiprocess)
tabela_spotify <- future_map_dfr(datas_charts_filtered, funcao_tabelas, .progress = TRUE)## # A tibble: 98,200 x 6
## Position TrackName Artist Streams Url Date
## <dbl> <chr> <chr> <dbl> <chr> <date>
## 1 1 A Gente Fez Amo~ Gusttavo ~ 521613 https://open.spotify~ 2020-05-05
## 2 2 Don't Start Now Dua Lipa 443213 https://open.spotify~ 2020-05-05
## 3 3 Liberdade Provi~ Henrique ~ 413044 https://open.spotify~ 2020-05-05
## 4 4 BRABA Luísa Son~ 394097 https://open.spotify~ 2020-05-05
## 5 5 Tudo no Sigilo Vytinho NG 364649 https://open.spotify~ 2020-05-05
## 6 6 Graveto - Ao Vi~ Marília M~ 349974 https://open.spotify~ 2020-05-05
## 7 7 Litrão - Ao Vivo Matheus &~ 342073 https://open.spotify~ 2020-05-05
## 8 8 Roses - Imanbek~ SAINt JHN 331409 https://open.spotify~ 2020-05-05
## 9 9 Rave de Favela ~ MC Lan 324164 https://open.spotify~ 2020-05-05
## 10 10 Ranking Jorge & M~ 303451 https://open.spotify~ 2020-05-05
## # ... with 98,190 more rowsUma ultima alteração: algumas músicas tem um complemento após o nome, como “- Ao Vivo” ou “(feat.)”. Vamos remover esses complementos para que diferentes versões de uma música sejam consideradas como uma só.
tabela_spotify <- tabela_spotify %>%
mutate(TrackName = str_remove(TrackName, " \\-.*| \\(.*"))Agora que temos nosso dataset, podemos partir para a segunda etapa do post.
Análise de dados
Vamos começar com duas perguntas básicas: quais os artistas e as músicas mais populares no Brasi durante o período?
tabela_spotify %>%
group_by(Ano = year(Date), Artist) %>%
summarise(Total = sum(Streams)) %>%
arrange(-Total) %>%
top_n(25, Total) %>%
ungroup() %>%
mutate(Artist = tidytext::reorder_within(Artist, Total, within = Ano)) %>%
ggplot(aes(x = Artist, y = Total)) +
geom_col(fill = "red") +
coord_flip() +
facet_wrap(~ Ano, scales = "free") +
scale_y_continuous(labels = unit_format(suffix = "M", scale = 1e-6)) +
scale_x_reordered() +
labs(x = "",
y = "",
title = "Marilia Mendonça é a artista mais popular do Brasil",
subtitle = "Baseado no número de streams do Spotify em 2019 e 2020")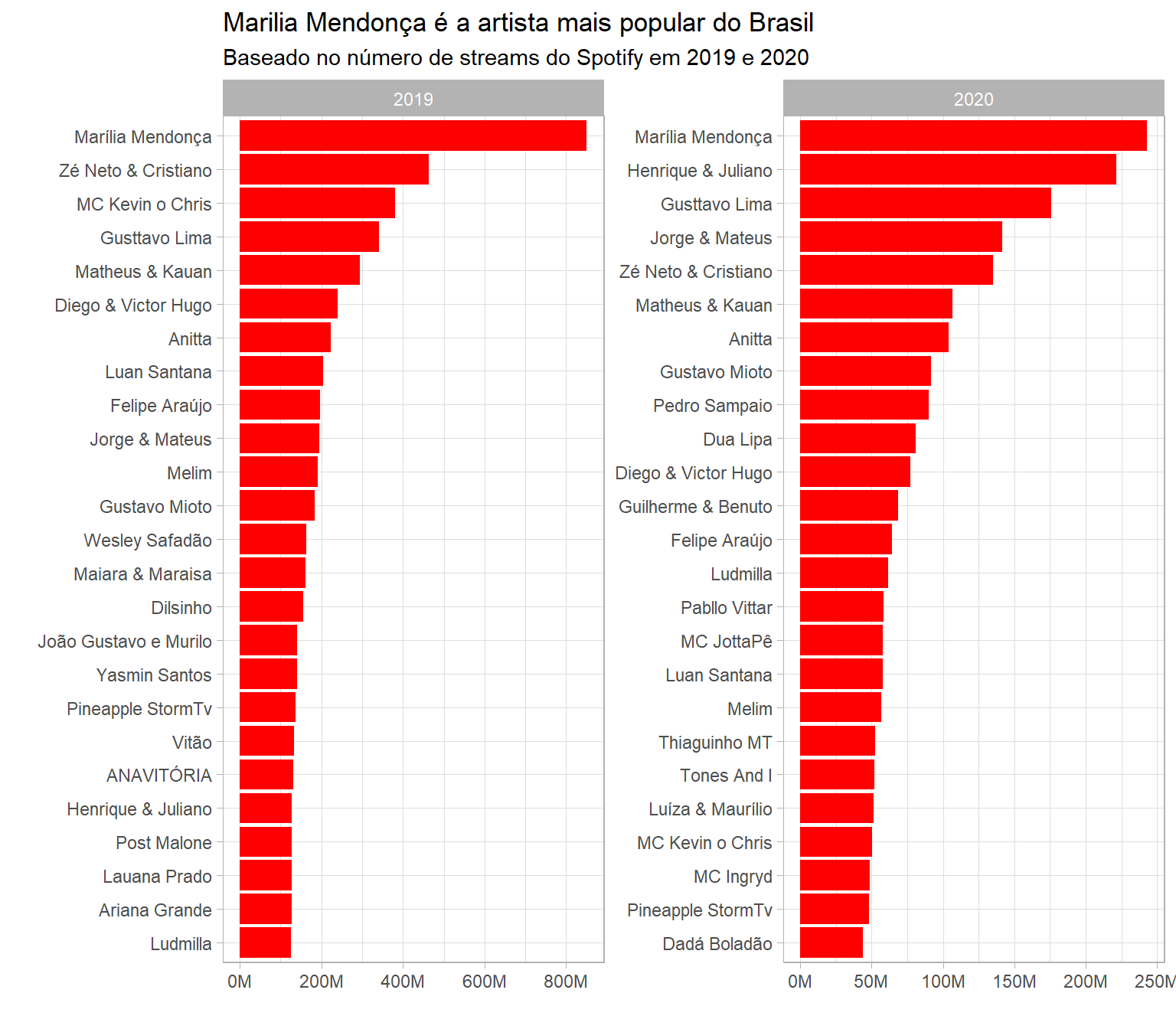
Clique abaixo para ouvir algumas das músicas da artista mais popular do Brasil:
tabela_spotify %>%
group_by(Ano = year(Date), TrackName) %>%
summarise(Total = sum(Streams)) %>%
arrange(-Total) %>%
top_n(25, Total) %>%
ungroup() %>%
mutate(TrackName = tidytext::reorder_within(TrackName, Total, within = Ano)) %>%
ggplot(aes(x = TrackName, y = Total)) +
geom_col(fill = "blue") +
coord_flip() +
facet_wrap(~ Ano, scales = "free") +
scale_y_continuous(labels = unit_format(suffix = "M", scale = 1e-6)) +
scale_x_reordered() +
labs(x = "",
y = "",
title = "Liberdade Provisória é a música mais tocada no Brasil em 2020",
subtitle = "Baseado no número de streams do Spotify")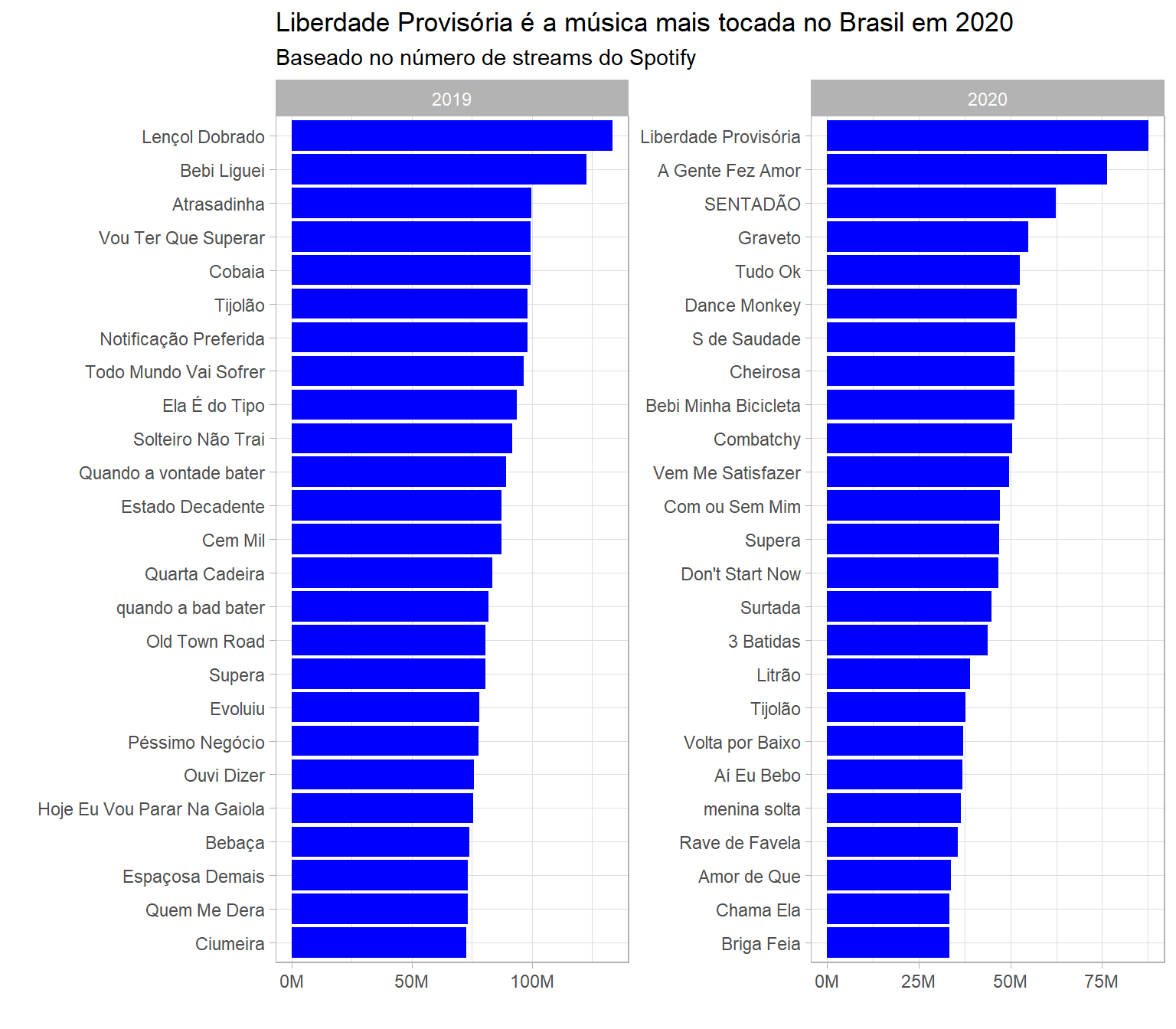
Clique abaixo para ouvir a música mais popular do Brasil em 2020 ate o momento:
Agora que sabemos quais as musicas e os artistas mais populares, vamos tentar detalhar um pouco mais essas informações, de maneiras diferentes. Para os artistas, faremos uma animação com o número acumulado de streams por semana no ano de 2020, ate chegar na semana atual que representa o gráfico anterior:
library(gganimate)
por_semana <- tabela_spotify %>%
filter(year(Date) == 2020) %>%
group_by(Artist) %>%
mutate(TotalArtista = sum(Streams)) %>%
ungroup() %>%
mutate(Artist = fct_lump(Artist, 20, w = TotalArtista)) %>%
filter(Artist != "Other") %>%
group_by(Semana = floor_date(Date, "week"), Artist) %>%
summarise(Total = sum(Streams)) %>%
ungroup() %>%
group_by(Artist) %>%
mutate(Acumulado = cumsum(Total)) %>%
group_by(Semana) %>%
mutate(Rank = rank(-Acumulado)) %>%
ungroup() %>%
mutate(Artist = as.factor(Artist)) %>%
select(-Total)
baseplot1 <- por_semana %>%
ggplot(aes(x = Semana, group = Artist, fill = Artist, color = Artist)) +
geom_bar(aes(y = Acumulado), stat = "identity", position = "dodge") +
theme(legend.position = "bottom")
baseplot2 <- baseplot1 +
coord_flip(clip = "off", expand = FALSE)
baseplot3 <- por_semana %>%
ggplot(aes(x = Rank,
group = Artist,
fill = Artist,
color = Artist)) +
geom_text(aes(y = 0, label = paste(Artist, " ")), vjust = 0.2, hjust = 1) +
coord_flip(clip = "off", expand = FALSE) +
geom_bar(aes(y = Acumulado), stat = "identity", position = "identity") +
theme(legend.position = "none",
axis.ticks.y = element_blank(),
axis.text.y = element_blank(),
axis.title.y = element_blank(),
plot.margin = margin(1, 1, 1, 5, "cm")) +
scale_y_continuous(labels = scales::comma) +
scale_x_reverse()
animp <- baseplot3 +
geom_text(aes(y = Acumulado,
label = as.character(Acumulado)),
color = "black", vjust = 0.2, hjust = .5) +
labs(title = "Semana {closest_state}",
y = "Total acumulado de streams") +
transition_states(Semana, transition_length = 5,
state_length = c(rep(.25, 18), 50), wrap = FALSE) +
ease_aes('linear') +
enter_fade() +
exit_fade()
animate(animp, fps = 10, duration = 20, width = 800, height = 450)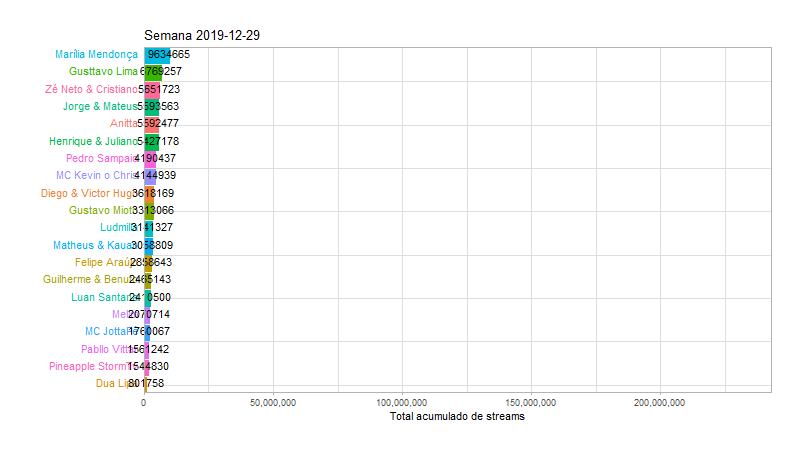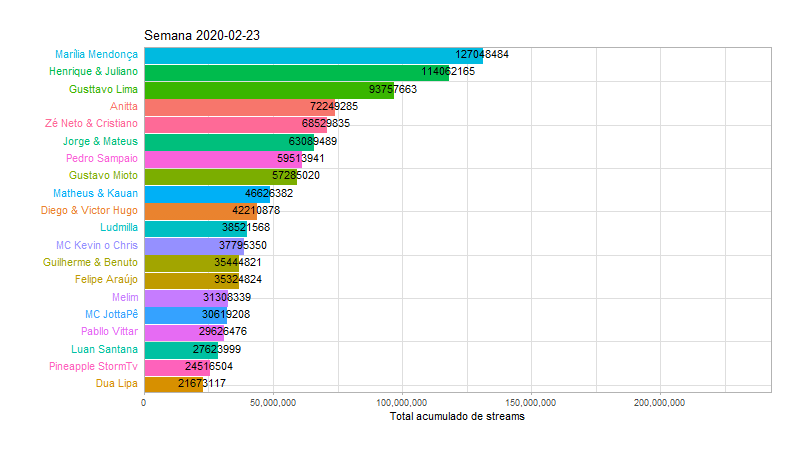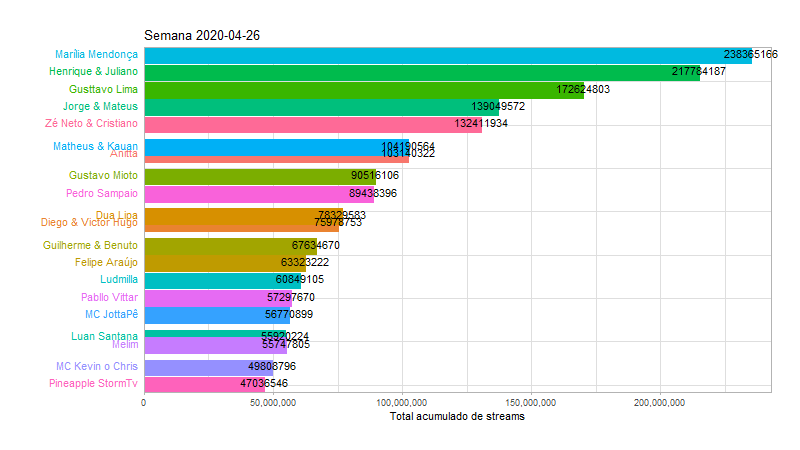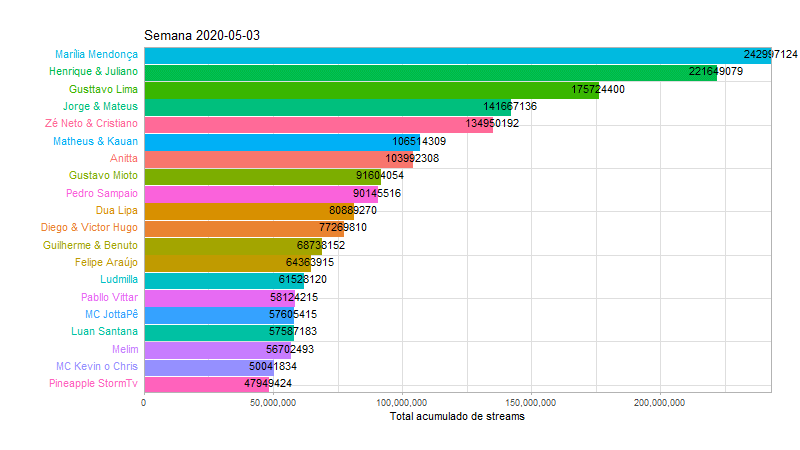
Ja para as músicas, pode-se perceber no gráfico anterior que a música mais popular de 2019 não aparece entre as mais populares de 2020 até o momento. Isso me levou a pensar sobre a duração do auge de popularidade de uma música. Assim, analisaremos as músicas mais populares ao longo de todo o período analisado, para descobrirmos quais foram as músicas de momento em diferentes épocas.
library(gghighlight)
tabela_spotify %>%
filter(Position == 1) %>%
mutate(TrackName = fct_lump(TrackName, n = 10, other_level = "Outras")) %>%
ggplot(aes(x = Date, y = Streams)) +
geom_col(aes(fill = TrackName)) +
scale_y_continuous(labels = unit_format(suffix = "M", scale = 1e-6)) +
scale_x_date(breaks = function(x) seq.Date(min(x), max(x), by = "2 month"),
date_labels = "%b/%y") +
labs(x = "",
y = "",
fill = "Musica",
title = "As musicas de momento no Brasil desde 2019",
subtitle = "Baseado nas músicas mais ouvidas por dia durante o período") +
theme(legend.position = "none",
axis.text.x = element_text(angle = 90, hjust = 0.5)) +
gghighlight() +
facet_wrap(~ TrackName)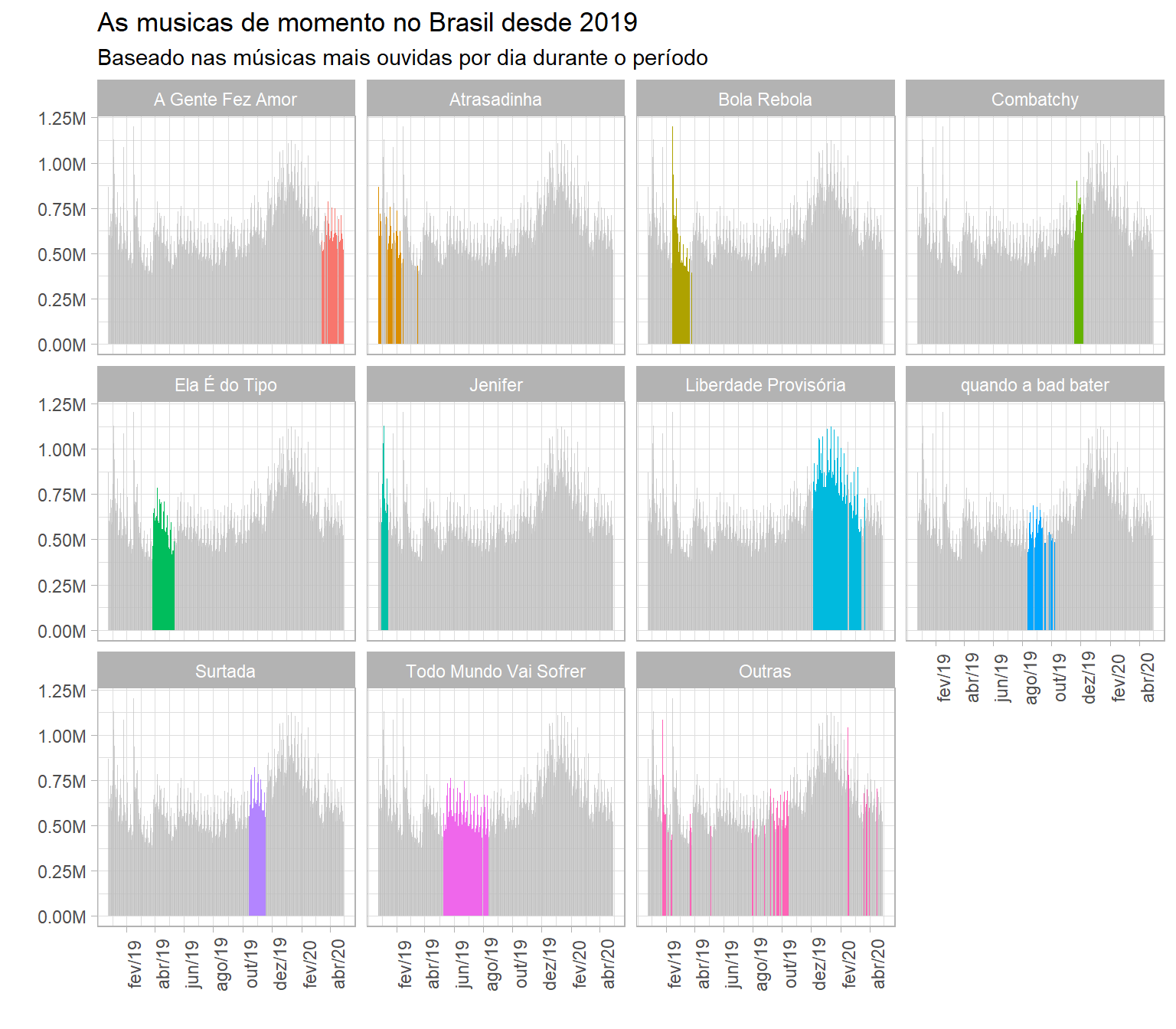
Fica claro quais músicas dominaram cada época de 2019 até o dia atual. No início do ano passado, por exemplo, a música do momento foi “Jenifer”. Já no meio do ano passado, o hit foi “Todo Mundo Vai Sofrer”. “Liberdade Provisória”, do Henrique & Juliano, teve o pico de popularidade mais longo, entre Dezembro e meio de Março, com uma breve interrupção no carnaval quando foi ultrapassado por “Tudo Ok”, do Thiaguinho MT. Já atualmente, a música mais popular é “A Gente Fez Amor”, conforme percebemos anteriormente.
Para evitar que o post fique muito longo, vamos finalizar por aqui. No entanto, há ainda muitas outras coisas interessantes a serem desvendadas com o nosso dataset, que pode servir também como um divertido instrumento de aprendizado de R. Caso você tenha alguma dúvida ou sugestão, fique a vontade para entrar em contato. Obrigado pela leitura!